Syllable structure
1. Problem and history
If syllables are coded in the canonical form, V, CV, CVC, etc. where the vowel (V) is the syllable nucleus and the consonant (C) is the periphery, we obtain a set of structural types whose number follows a specific two-dimensional distribution. The types can be presented in tabular form

Where the frequency of the type CVVCC is given as n12, i symbolizing the number of consonants before and j that behind the nucleus. There are at most r onsets and s codas in the syllable. Let 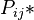 be the corresponding probability.
be the corresponding probability.
2. Hypothesis
The distribution of canonical syllable types abides by the (modified) bivariate Conway-Maxwell-Poisson distribution.
3. Derivation
Starting from the unified theory we assume that the probabilities of syllable types are joined with the following proportionality relation
(1)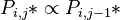
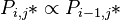
i.e. a class is proportional to its left or upper neighbour. In the first step Zörnig and Altmann (1993) used the simple Menzerathian relatioship (see Hierarchic relations) as proprotionality function and obtained
(2)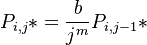
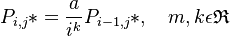
The solution of (2) yields
(3)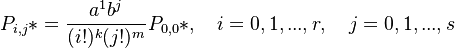
where the norming constant is 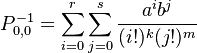 .
.
Since the particular case examined (Indonesian) has a strong preference for the CVC type ( = 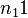 ) the distribution must be modified and renormed. Weighting
) the distribution must be modified and renormed. Weighting 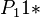 by β the other probabilities must be weighted so that
by β the other probabilities must be weighted so that 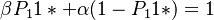 . As a result we obtain
. As a result we obtain
(4)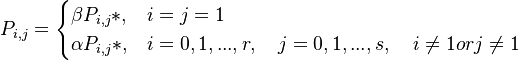
Zörnig and Altmann (1993) show also the estimators won from frequency classes as
(5)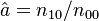
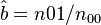
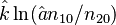
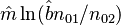
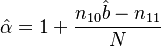
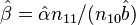
Example. Structure of Indonesian syllables
In about 15000 Indonesian word forms from different texts Zörnig and Altmann (1993) found 610 syllable types shown in Table 1.

Using (3), (4) and (5) they obtained
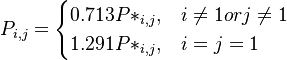
with
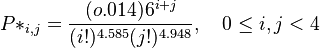 .
.
The estimated parameters are: a = b = 6, k = 4.585, m = 4.948, α = 0.713, β = 1.291, 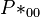 = 0.014, N = 610 and the fitting is presented in Table 2. For example
= 0.014, N = 610 and the fitting is presented in Table 2. For example 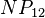 is computed as
is computed as
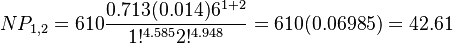 .
.

The result is acceptable without testing.
4. Authors: U. Strauss, G. Altmann
5. References
Lee, Sank-Oak (1986). An explanation of syllable structure change. Korean Language Research 22, 195-213.
Vennemann, T. (1982) (ed.). Zur Silbenstruktur der deutschen Standardsprache. Silben, Segmente, Akzente: 261-305. Tübingen: Narr.
Zörnig, P., Altmann, G. (1993). A model for the distribution of syllable types. Glottometrika 14, 190-196.