Compounds and polysemy
1. Problem and history
The building of compounds from a stem (word, lexeme, morpheme) depends on different factors, one of them being polysemy and other ones frequency, length, polytexty, word class, age of the stem, etc. Some hypotheses have been collected by Altmann (1989,  Compounds: further hypotheses) but derivations and testing is not yet advanced. The most complex problem is the operational definition of the compound word which can be different for different languages. The law could, perhaps, help us to decide for a special definition.
One of the hypotheses considered several times is the relation between polysemy and compounding. The start was made by Rothe (1988) who considered it special case of Menzerath´s law and especially by Steiner (1995, 2002) who embedded the problem in the framework of synergetic linguistics (see also Krott 2002). Steiner speaks rather about “composition activity”. Rothe took a sample and Steiner considered the complete German dictionary.
Below we show a simple dependence, but the problem should be treated as a multidimensional one, i.e. there are always more factors affecting the properties of the compound.
Compounds: further hypotheses) but derivations and testing is not yet advanced. The most complex problem is the operational definition of the compound word which can be different for different languages. The law could, perhaps, help us to decide for a special definition.
One of the hypotheses considered several times is the relation between polysemy and compounding. The start was made by Rothe (1988) who considered it special case of Menzerath´s law and especially by Steiner (1995, 2002) who embedded the problem in the framework of synergetic linguistics (see also Krott 2002). Steiner speaks rather about “composition activity”. Rothe took a sample and Steiner considered the complete German dictionary.
Below we show a simple dependence, but the problem should be treated as a multidimensional one, i.e. there are always more factors affecting the properties of the compound.
2. Hypothesis
The greater the polysemy/polylexy of a stem/lexeme, the more compounds it forms.
The wording is different with Rothe and Steiner but the meaning of the hypothesis is the same. This is the same relation as between polysemy and word length since words are prolonged by affixation, compounding, reduplication etc.
3. Derivation
The relative rate of change of the number of compounds (dy/y) built from a stem is proportional to the relative rate of change of its polysemy (x), i.e.
(1)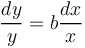
resulting in
(2)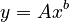 .
.
Example. Polysemy and compounds in German (Rothe 1988)
Rothe took a sample of 1858 lexemes form “Wahrig: Deutsches Wörterbuch” (1985) and tested the hypothesis separately on nouns, verbs, adjectives/adverbs and on the complete sample. Since the independent variable is the number of meanings, the number of compounds has been averaged. For the nouns, Rothe obtained the results shown in Table 1 and Fig. 1.


Here the fitting is good but some data display greater dispersion. A multidimensional approach would probably improve the results.
4. Authors: U. Strauss, G. Altmann
5. References
Altmann, G. (1989). Hypotheses about compounds. Glottometrika 10, 100-107.
Altmann, G., Bagheri, D., Goebl, H., Köhler, R., Prün, C. (2002). Einführung in die quantitative Lexikologie. Göttingen: Peust & Gutschmidt.
Krott, A. (2002). Ein funktionalanalytisches Modell der Wortbildung. In: Köhler, R. (ed.), Korpuslinguistische Untersuchungen in die quantitative und systemtheoretische Linguistik: 75-126. http://ubt.opus.hbz-nrw.de/volltexte/2004/279/.
Rothe, U. (1988). Polylexy and compounding. Glottometrika 9, 121-134.
Sambor, J. (1984). Menzerath's law and the polysemy of words. In: J. Boy & R. Köhler (Hg.), Glottometrika 6, 94-114. Bochum: Brockmeyer.
Sambor, J. (1989). Polnische Version des Projekts "Sprachliche Synergetik. Teil I. Quantitative Lexikologie". In: R. Hammerl (ed.), Glottometrika 10, 171-197. Bochum: Brockmeyer.
Steiner, P. (1995). Effects of polylexy on compounding. J. of Quantitative Linguistics 2, 133-140.
Steiner, P. (2002). Polylexie und Kompositionsaktivität in Text und Lexik. In: Köhler, R. (ed.), Korpuslinguistische Untersuchungen in die quantitative und systemtheoretische Linguistik: 209-251. http://ubt.opus.hbz-nrw.de/volltexte/2004/279/